In this session, we are going to learn two types of Artificial Neural Networks (ANNs): Multi-layer Perceptron (MLP) and Convolutional Neural Networks (ConvNets). These ANN architectures are also Feedforward Networks (FNNs). We will show how they works and the links between them. In addition, we will also learn regularization techniques that improve generalization during training.
Deep Learning: Another Victim of the CS Naming Logic
Deep Learning (DL) is a terrible name. First of all, there is no concrete definition of the term “deep”. In the influential review article Deep Learning in Neural Networks: An Overview, Schmidhuber says:
At which problem depth does Shallow Learning end, and Deep Learning begin? Discussions with DL experts have not yet yielded a conclusive response to this question. Instead of committing myself to a precise answer, let me just define for the purposes of this overview: problems of depth require Very Deep Learning.
Remark: We encourage you to check out this fascinating review of Deep Learning.
Instead of the term “deep”, “hierarchical” might be more suitable. However, modern (in last two years) DL models cannot simply be characterized by “hierarchical” anymore (e.g., Neural Turning Machine models).
The second part of the name “Learning” is also a misleading word. The “learning” process (via training) intends to improve the generalization in unseen examples. However, the concept does not associate with “learning” in the biological sense. The entire “learning” process is carried out by some powerful optimization algorithms (we called them “training” algorithms).
This is another example where computer scientists gave a terrible yet catchy name (the first example is “Computer Science” itself, check here for reason). Yann LeCun, one of the founding fathers of DL, proposed to rename “Deep Learning” to “Differentiable Programming” in a recent Facebook post. This is by far the most accurate definition. First, all modern DL models up to date are differentiable. Second, the optimization algorithms finds a set of optimal parameters that “program” the model to exhibit some desired behaviors.
We have to remember that DL consists of many useful and powerful tools. However, DL alone is not AI, or Machine Learning.
Remark: To be exact, differentiable models are the largest family of DL models. However, there are DL models that are not differentiable and do not use SGD to optimize (e.g., some Reinforcement Learning algorithms).
Artificial Neuron
Artificial Neural Networks (ANNs) are machine learning models that are inspired by neuroscience findings and are constructed by a mathematical abstraction of the functionality of biological neurons.

An artificial neuron.
An artificial neuron receives a vector of input , and the output is determined by the activation function of the weighted sum of the input vector and an optional bias value. Popular choices of activation functions are
where (the linear equation we have seen before), ReLU stands for “Rectified Linear Unit”. Note that in practice there are more activation functions available (e.g., Leaky ReLU, ELU, softplus).
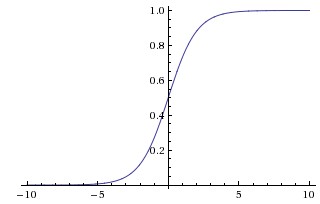
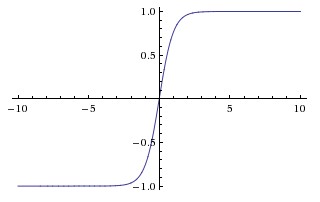
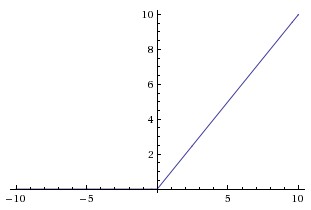
Left: the Sigmoid function; Middle: the tanh function; Right: the ReLU function.
Sigmoid function was very popular because (a) the function has a range between 0 to 1 so that one can interpret the level of activation to some meaning (e.g., probability, degree of activation); (b) the function is more “biological plausible” than other activation functions for our artificial neuron model. However, in practice, the Sigmoid function has some very undesirable properties. One of the most significant issues is that the gradient of the neuron reaches to zero when the activation of the neuron saturates at the tails of the function. When the gradient is close zero, the parameters that are associated with the neuron cannot be effectively updated.
tanh is the scaled and shifted version of the Sigmoid function (). This function squashes the function input to the range . Compared to the Sigmoid function, the function is zero-centered although it still has the saturation problem. In practice, one always prefers to use the function than the Sigmoid function.
ReLU becomes very popular in the last few years after the seminal work ImageNet Classification with Deep Convolutional Neural Networks by Alex Krizhevsky, et al. was published in 2014. The function greatly accelerates the training compared to the Sigmoid or functions. Additionally, ReLU is very cheap to compute. The ReLU function has its problems as well. For example, a neuron may not be activated by any inputs (e.g., always outputs zero) from the entire dataset if the neuron experienced a large gradient flow. And because the ReLU is an open-ended function, the training may suffer from instability if the network has too many layers.
Remark: Although ReLU function is the most common choice of the activation function, the Sigmoid or function have their market. In particular, they are preferable in Recurrent Neural Networks (RNNs) where the neuron receives feedback signals.
Remark: The artificial neuron model is inspired by neuroscience findings and can solve many different problems. However, one should not over-explain its connection with neuroscience because the model can be analyzed without any neuroscience knowledge.
A group of artificial neurons can be organized into a layer. A layer is the building block of ANNs. Interactions between and within layers shape the dynamics of the neural networks.
Multi-layer Perceptron
The Multi-layer Perceptron (MLP) network is a canonical Feedforward ANN architecture. Let’s firstly define its parent class - FeedForward Neural Network (FNNs) before discussing the MLP networks.
FNNs are a class of ANNs where the computation flows in a single direction: there is no feedback connection between layers. An FNN consists of layers where each layer is defined by its parameters , which are referred to as weights and biases respectively. An activation function maps the layer input to layer output :
An alternative view of FNNs is that the network computes a composition of functions (Goodfellow et al., 2016; Poggio et al., 2017):
Note that the above formulation omits the method of computation between the layer input and the parameters . The result before applying the activation function is called pre-activation and denoted as .
Now, we can describe the MLP network in a similar manner. Suppose the -th layer has neurons and -th layer has neurons, and the parameters , . The input activation from -th layer , the activation of -th layer can be computed by:
A Keras example is as follows:
x = Dense(100)(x) # the layer has 100 neuron
x = Activation("relu")(x) # the activation function is ReLU
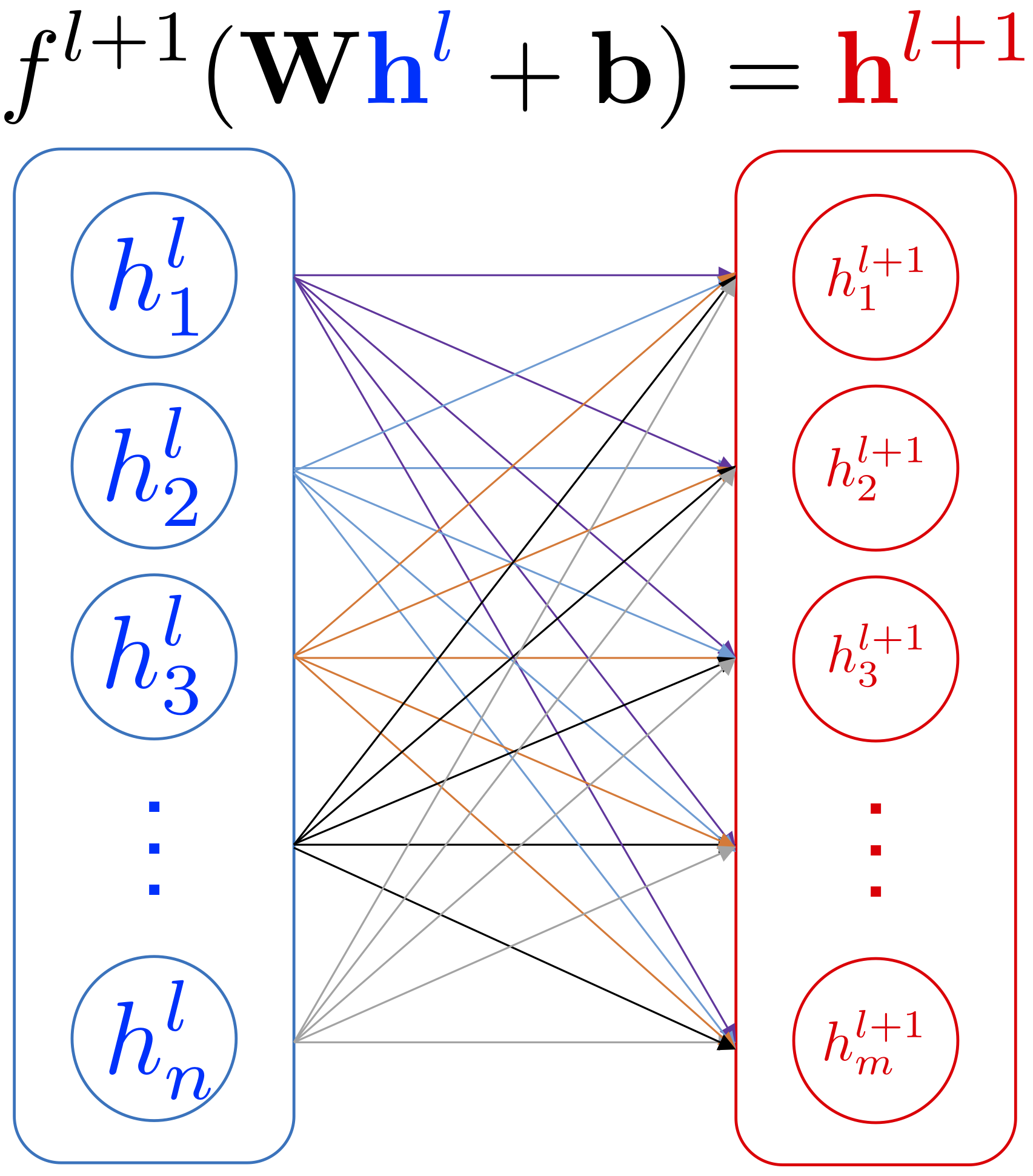
Example of MLP hidden layers.
Conventionally, we call the first layer as the input layer, the last layer as the output layer, and the rest of layers as hidden layers. The input layer has a special array of neurons where each neuron has only one input value. The parameters are fixed as where is the identity matrix. The activation function for the first layer is the linear activation .
Note that from the architecture point of view, MLP network is a generalization to Linear Regression and Logistic Regression (see Session 2). Linear Regression and Logistic Regression are two-layered MLP networks. Furthermore, the activation functions of the Linear Regression and Logistic Regression is and respectively.
The most profound mathematical argument on the MLP network may be the Universal Approximation Theorem. This theorem states that an MLP network with a single hidden layer that contains a finite number of neurons can uniformly approximate the target function with arbitrary precision. This theorem was first proved by George Cybenko in 1989 for Sigmoid activation functions. This theorem then generated a huge influence on researchers back in the 1990s and early 2000s. Because a three-layered MLP network is a universal function approximator, researchers refused to go beyond three layers given limited computing resources at the time. However, the theorem does not give any information on how long the network takes to find a good approximation. And in practice, we usually found that it is usually very time costly compared to deeper architectures.
Remark: Because the MLP layer densely connects all the neurons between two layers, it is also referred to as Fully-Connected Layer or Dense Layer.
Remark: Shun’ichi Amari wrote a brilliant article titled Neural theory of association and concept-formation in 1977. This paper explained how the neural networks could perform unsupervised learning and supervised learning. Amazingly, it also showed how MLP-kind network could be trained via gradient descent.
Convolutional Nerual Networks
Convolutional Neural Networks (ConvNets) is another type of FNN (Lecun et al., 1998). ConvNets explicitly proposed to work with images. Furthermore, we can show that this model generalizes the MLP networks. ConvNets significantly accelerates the renaissance of neural networks (Krizhevsky et al., 2012). They have proven to be great architectures for achieving state-of-the-art results on visual recognition tasks, e.g., image and video recognition (Simonyan & Zisserman, 2014; Szegedy et al., 2015; Ji et al., 2013), object detection (Ren et al., 2015; Liu et al., 2015) and image caption generation (Karpathy & Li, 2015; Vinyals et al., 2016). Recent results show that certain types of ConvNets achieve comparable performance in Natural Language Processing (NLP) tasks against RNNs (Zhang et al., 2015; Kalchbrenner et al., 2016).
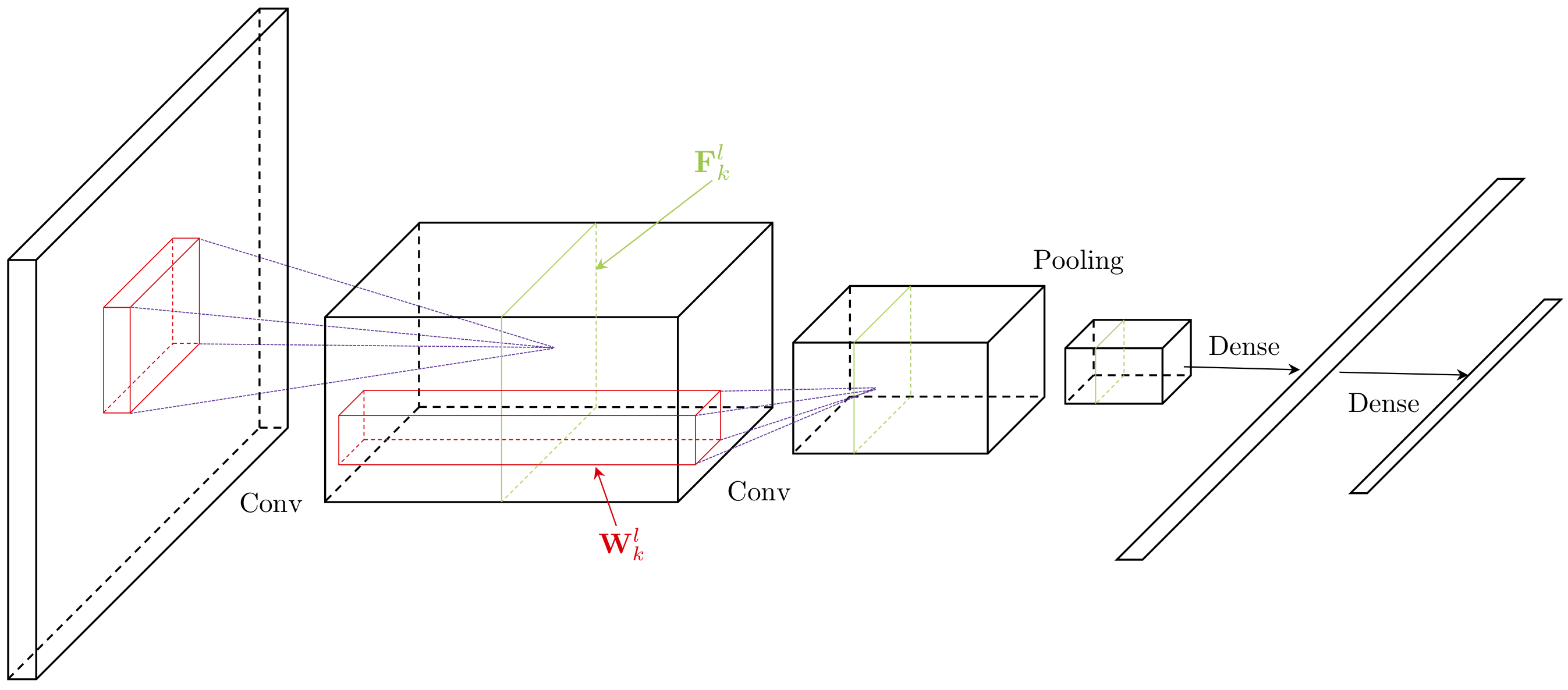
ConvNets usually consist of convolution layers, pooling layers, and dense layers.
Convolution Layer
ConvNets heavily use 2D convolution on 3D tensor. Informally, 2D convolution can be viewed as a filtering process where you have a filter that applies to the input tensor. Let’s consider a concrete example where you have a binary image and a binary filter. The valid convolution can be performed by using the filter as a sliding window and applying convolution operation at every possible position, the filter and the covered region does an element-wise multiplication and summation. See the example as follows:
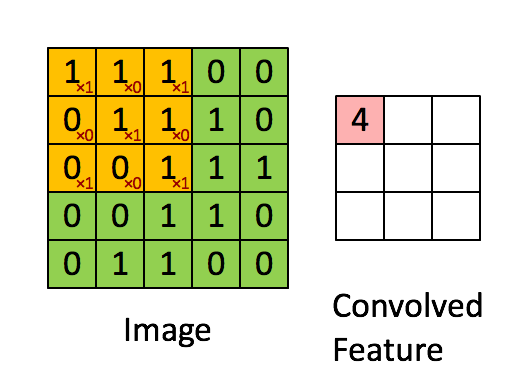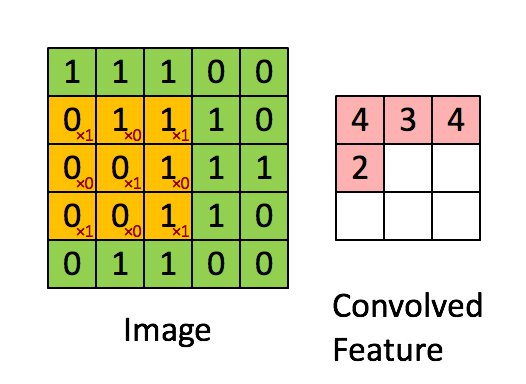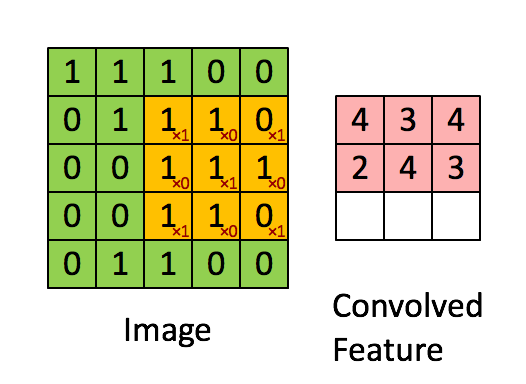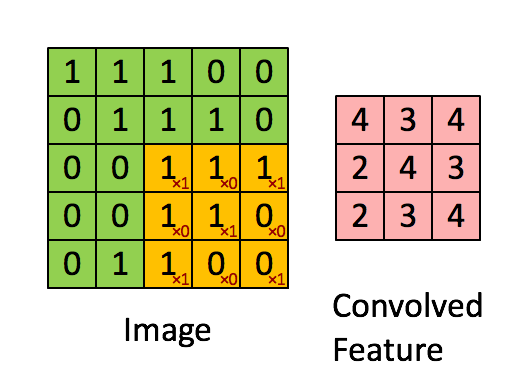
2D convolution on a 5x5 binary image with a 3x3 filter. Image Credit: UFLDL
For example, when the filter is covered the top-left corner, the output value can be computed by
More generally, if the input image has the dimension of and the filter size is , the output size of the convolved output is . This convolved output is usually referred to as a feature map. Commonly, we call the input of a convolution layer as the input feature map(s) and the output as the output feature map(s).
In the above example, the input binary image has only one channel that means the image is a 2D array. However, an RGB image usually has three channels where these channels represent the red intensity, the green intensity, and the blue intensity correspondingly. The mixture of these three channels produces a color image. How can a convolution layer deal with the input that has multiple channels? The answer is that we also give more channels to the filter. Suppose that the input has channels (or feature maps), the filter will also have channels. First, each channel of the filter is applied on the corresponding channel of the input. Second, the convolved outputs of all feature maps are summed along the axis of the channels so that they are combined into one output feature map. A visual example is given as follows
Convolution on a 3x7x7 image with two 3x3x3 filters. Image Credit: CS231n
In above example, the input feature map is a 3D tensor, and respectively, the filter is also a 3D tensor. In ConvNets, every convolution layer usually has filters; each filter can generate one output feature map. Hence, the filters of a convolution layer can be characterized as a 4D tensor number of filters x number of channels x height of filters x width of filters. The input feature map is then transformed from a 3D tensor to another 3D tensor.
Remark: The number of channels/feature maps is also called the depth of the layer input and output.
Remark: We use “feature map” and “channel” interchangeably for describing the layer input and output. For filters, we only use the term “channel” for describing its depth.
Additionally, there are two configurations for defining the convolution layer: padding and strides. The padding operation pads additional rows and columns to each channel of the input feature maps. Usually, the operation pads a constant value such as 0. In some cases, one might append values that are generated from some distribution. The stride describes how we slide the filters. When the stride is 1, then we move the filters one pixel at a time. When the stride is 2, then the filters jump two pixels at a time. The above example has a stride that is equal to two in both horizontal and vertical directions. A Keras example is as follows:
x = Conv2D(filters=10, # this layer has 10 filters
kernel_size=(3, 3), # the filter size is 3x3
strides=(2, 2), # horizontal stride is 2, vertical stride is 2
padding="same")(x) # pad 0s so that the output has the same shape as input
x = Activation("relu")(x)
With the informal description above, we can now formally describe the convolution layer. The weights of the -th convolution layer can be defined as a 4D tensor where the dimension of the tensor is determined by number of filters , number of channels , the height of the filters and the width of the filters (e.g., ). The bias is a 1D tensor where the length is equal to the number of filters (e.g., ). Let the input feature maps be a 3D tensor where the dimension is defined as number of feature maps , the height of the feature map and the width of the feature map (e.g., ). Note that the MLP network is a special case when .
The above equations demonstrate the convolution operation by using the -th filter. The output of the layer includes the activations (output feature maps) from all filters . Note that the above equations do not include zero-padding and stride parameters. Each element in the output feature maps is a neuron, and the value of the element represents the activation of the neuron. Under this construction, consequently, each convolution layer usually has much fewer parameters than an MLP layer. At the same time, a convolution layer uses a lot more computing resources than an MLP layer. To compute one feature map, the corresponding filter is repeatedly used. This feature of the convolution layer is called weight sharing.
The last topic of this section is to calculate the output feature maps’ tensor shape given the horizontal padding , the vertical padding , the horizontal stride and vertical stride , the output feature maps’ tensor shape is:
Note that in practice, we prefer to process a batch of 3D tensors instead of one. Therefore, usually, we define the input of the convolution with an additional dimension that represents the batch_size. The input feature maps can be characterized as a 4D tensor as well: batch_size x number of feature maps x height of feature maps x width of feature maps.

96 Filters from the first convolution layer learned by Krizhevsky et al. Each filter has a shape of 11x11x3. These filters mostly respond to edges, colors. Image Credit: CS231n
Remark: Readers may recognize that the above examples compute “correlation” instead of “convolution”. The correct convolution requires filter flipping where one needs to transpose every channel of a filter. However, to demonstrate how the convolution is performed, we assume that all the filters have been “flipped”.
Pooling Layer
Another important component of ConvNets is pooling. The pooling operation is inspired by the complex cells in the Primary Visual Cortex (V1) (Hubel & Wiesel, 1962). It serves as a way of sub-sampling and invariance. Max-pooling and average-pooling are notable examples of pooling operations which are widely applied in DNNs.
In many ways, one can view the pooling layer as a variant of the convolution layer. Although this claim is not correct in general, this can help you understand the concept. Let’s consider a filter that has the size (the pooling size) can carry out the pooling operation on a feature map. We also define the padding parameters , , and the stride parameters , . Now we slide this filter on the target feature map as the same as the convolution process. At each covered region, instead of computing the weighted sum of the region, the filter applies a predefined function that extracts/computes the output value. The same filter carries out the same process to all other input feature maps. At the end of the pooling operation, the height and width of the output feature maps may be different from the input feature maps. However, the number of the feature maps remains the same. The tensor shape of the output feature maps can be calculated:
In principle, one can parameterize the predefined pooling function . Because the pooling layer is usually served as a way of sub-sampling, we often do not introduce extra parameters for the pooling function. We also rarely introduce any extra padding because of the same reason. Conventionally, we set the stride as the same as the pooling size (e.g, , ). This way, the covered regions are not overlapped while the filter is moving. We commonly call this as “non-overlapping pooling”. In some situations, you can set the stride smaller than the pooling size. We hence refer this case to as “overlapped pooling”.
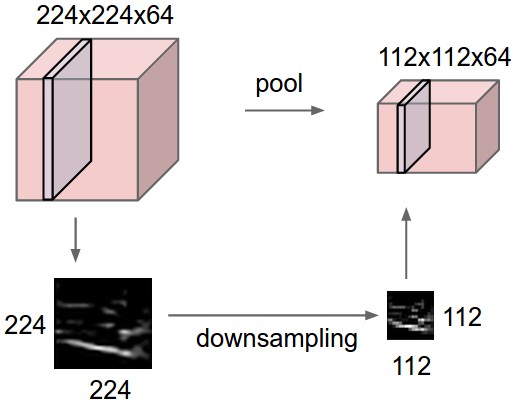
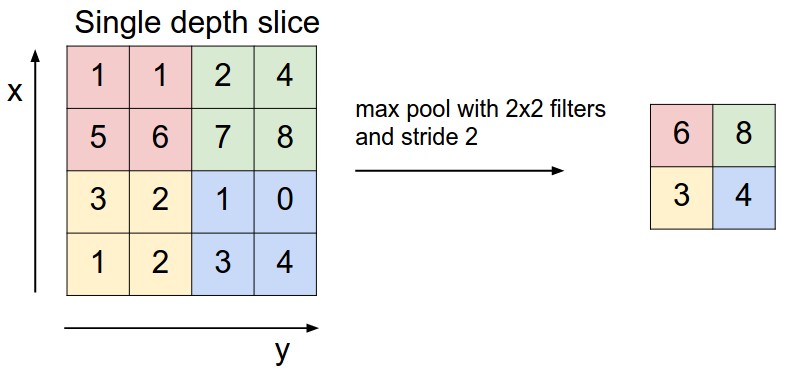
The rest of this section discusses two popular types of pooling: Max-pooling and Average-pooling.
The max-pooling selects the maximum value in the covered region and omits all other values. The max-pooling operation implements a certain degree of “translation invariance” at small scale because if the input feature maps have a small shift, the same maximum value can still be selected. Given a set of input feature maps , for each input feature map where , the output feature map can be computed via the following equation:
where the (the row index) and (the column index) start from 0. We also assume that the padding has been done beforehand. A Keras example is given as follows:
x = MaxPooling2D((2, 2))(x) # perform max-pooling over 2x2 non-overlapping region
The average-pooling operation computes the average activation of the covered region:
A Keras example is given as follows:
x = AveragePooling2D((2, 2))(x) # perform average-pooling over 2x2 non-overlapping region
In practice, there are two kinds of special cases of max-pooling and average-pooling that are widely employed: global max-pooling and global average-pooling. The global max-pooling and average-pooling has the configurations where , , the padding is set to zero and stride is set to one.
Note that in section, we only describe the pooling layers for 2D feature maps. There are other variants in Keras implementation that can deal with 1D or 3D feature maps.
Remark: Recently, people tend to use convolution that has larger strides to replace the pooling operation for sub-sampling, such as ResNets.
Flatten and Dense Layers
The output of convolution and pooling layers for a single sample is organized in a 3D tensor. And commonly, we would like to reorganize this tensor to a 1D vector so that we can manipulate all “information” carried by the output easily. This process is called flatten. The flatten operation simply “stretch” an -D tensor into a 1D vector. In Keras, you can use the Flatten layer to do this job:
x = Flatten()(x)
Note that we always assume that the first dimension is reserved for batch_size and the flatten operation does not affect the first dimension. For example, if you flatten an input 4D tensor with the size (64, 10, 20, 3), the flattened output is a 2D tensor with the size (64, 10x20x3).
One main reason for performing the flatten operation is to append more MLP layers (see above figure). Because MLP layers only receive 1D vector as inputs, we will have to flatten the output of convolution layers before sending it into the MLP layers. In practice, we usually refer MLP layers to as Dense layer or Fully-Connected layer.
Note that it is possible to convert a 1D vector back to a 3D tensor via reshaping. This operation is sometimes used in practice if your desired output is characterized as a 3D volume.
Remark: The development of modern ConvNet-based architectures is beyond the scope of this module. But we do encourage readers to check out some seminal works in this fields, such as AlexNet, GoogLeNet, VGGNet, OverFeat, ResNet.
With Keras, you can save your compiled model into a directed graph image, this model image can also provide additional information about the tensor shape of each layer. e.g.,
from keras.utils import plot_model
plot_model(model, to_file='model.png',
show_shapes=True)
Regularization
Regularization techniques in DNNs research help to reduce the network generalization error which is the difference between training and testing errors. These techniques usually bound the weights, stabilize training, and increase robustness against adversarial examples of the network. This section introduces Regularization, Dropout and Batch Normalization (BN) (Ioffe & Szegedy, 2015). A more informative review of regularization in Deep Learning can be found in Goodfellow et al. (2016).
Regularization
regularization is commonly referred to as weight decay. It has been broadly applied in DNNs in order to control the squared sum of the trainable parameters . To apply regularization, one modifies the original cost function to :
where is a small constant that controls the weight decay speed. A Keras example is given as follows:
from keras import regularizers
x=Dense(64,
kernel_regularizer=regularizers.l2(0.01))(x) # add L2 regularization on weights of this layer
Intuitively, as the regularization applies the constraints on the weights, it reduce the effects of overfitting by decreasing the magnitude of the weights.
Usually, regularization is not applied to the bias terms and only makes small difference if it applies to the bias terms. Note that in some books, the control parameter is written as . This style of formulation helps while deriving the gradient updates.
Remark: Regularization is also known as ridge regression or Tikhonov regularization.
Dropout
Dropout is a simple yet effective regularization technique for mitigating the overfitting (Srivastava et al 2014). Dropout first computes a binary mask where % of the elements of the mask are set to zero stochastically. Then, the mask and the incoming layer inputs performs a element-wise multiplication. Finally, the masked output is used as the layer input. This binary mark switches the neuron off by turning the activation to zero. Hence, the neuron would not be updated in the next gradient update.
Note that this process is only performed during the network training so that the generalization could be improved. It switches off during the testing/inference phase. A Keras example is given as follows:
x = Dropout(0.3)(x) # 30 of the neurons are dropped
The dropout purposely adds noise to the system so that during training, the network is forced to make correct predictions with imperfect inputs. This process hence improves the robustness of the network to test samples.
Another way to explain the dropout is the network resemble view. Because at each batch training, the network switches % neurons off, the masked network is trained while the weights of the other neurons are not updated. After training, since the dropout is not applied, we can intuitively view that all the masked networks during training are combined to produce prediction simultaneously.
Remark: From the formulation, Dropout connects to another classical architecture - Denoising Autoencoder. Interested readers can check out this architecture.
Batch Normalization
Batch Normalization (BN) was proposed as a strategy for reducing internal covariate shift (Ioffe & Szegedy, 2015). Internal covariate shift is characterized as “the change in the distribution of network activation due to the change in network parameters during training”. Mathematically, BN is defined as:
where the equation takes the layer’s output activation and normalizes it into , and are trainable parameters that are called scale and shift parameters respectively, and is a small regularization constant. A Keras example is as follows:
x = BatchNormalization()(x) # perform BN on the input
The use of BN in DNNs greatly smooths the network training in practice. It is not used as a default component in many DNNs architectures (e.g., ResNets). The application of BN in RNNs is recently explored in Cooijmans et al. (2016).
Note that one has to perform BN in both training and inference phases. The only difference is that during the inference phase, the trained and parameters are not updated anymore. Furthermore, there are techniques to rescale the trained weights according to BN’s trained parameters so that one can avoid BN’s calculation during the inference phase. We omitted this details because this is out of the scope of this module.
Remark: Since the Batch Normalization was proposed, there is a trend of abandoning Dropout as the Dropout seems to make a small difference in training.
Exercises
-
In this exercise, you will need to implement a multi-layer perceptron to classify the images in the Fashion-MNIST dataset into ten classes. As in last week, you will be provided with a template script with the barebone structure of the implementation. You will need to complete the script by defining a multi-layer perceptron model with two hidden layers of 100 units each, each with ‘relu’ activation, using Keras layers, compile the model with the categorical cross entropy loss and an optimizer of your choice, and train the model. Note the performance of the model after every epoch and also note the number of parameters in the model.
-
In this exercise, you will need to implement a convolutional neural network to classify the images in the Fashion MNIST dataset into ten classes. You will be provided with a template script with the barebone structure of the implementation. You will need to complete the script by defining a convolutional neural network as described below, using Keras layers, compile and train the model as in the above exercise. Compare both the performance of this model and also the number of trainable parameters in this model to the multi-layer perceptron model trained in the above exercise.
The convolutional neural network has a convolution layer with
20kernels of size7x7each, with areluactivation followed by max pooling with a pool size of(2, 2)and a stride of(2, 2). This is followed by another convolution layer with25kernels of size5x5each, with areluactivation followed by max pooling with a pool size of(2, 2)and a stride of(2, 2). Now flatten the 2D output from the previous layer and apply a linear transformation to a space with200units, with areluactivation, followed by another linear transformation into10units. Use asoftmaxactivation on the final layer to train the model as a classifier.
-
In this exercise, you will need to implement a multi-layer perceptron as in the first exercise, but you will not be using the Keras layers but build the model from scratch like in the second exercise from last week. You will have to build a multi-layer perceptron with arbitrary number of layers with arbitrary number of units in each of the layer. You can assume the number of layers is given by a variable
num_layersand set it to 2 like in the first exercise, and the number of units in each of the layer can be assumed to be encoded in a listnum_unitsand set it to[100, 100]like in the first exercise. You will have to create the necessary input and target placeholders, create the necessary variables of appropriate shapes, perform the necessary operations as in a multi-layer perceptron, define the loss based on the model prediction and the target, and then define the gradients of the loss with respect to the variables in the model. Then you will have to define the train_function and the test_function like in the last model. You will be provided with a template script to help you with the peripheral script. -
(Optional) Try to improve your first two exercises by using different regularization such as Dropout and Batch Normalization.
-
(Optional) Copy your first exercise’s answer to a different script, and modify your network to a 30-layered MLP network where each layer has 20 neurons, can you still train the network? This exercise relates to the fundamental challenge of the DNNs - the vanishing gradient problem.